七、设计分布式系统中的唯一 ID 生成器
在这一章中,你被要求在分布式系统中设计一个唯一的 ID 生成器。您首先想到的可能是在传统数据库中使用带有 auto_increment 属性的主键。然而, auto_increment 在分布式环境中不起作用,因为单个数据库服务器不够大,并且在最小延迟的情况下跨多个数据库生成唯一的 id 具有挑战性。
这里有几个唯一 id 的例子:

步骤 1 -了解问题并确定设计范围
提出澄清性问题是解决任何系统设计面试问题的第一步。下面是一个应聘者与面试官互动的例子:
候选人 :唯一 id 有什么特点?
采访者 :身份证必须是唯一的,可排序的。
候选人 :每增加一条新记录,ID 增加 1 吗?
面试官:ID 随时间递增,但不一定只递增 1。同一天晚上创建的 id 比早上创建的 id 大。
候选人:id 只包含数值吗?
面试官 :是的,没错。
考生 :身份证长度有什么要求?
采访者 :身份证应该是 64 位的。
候选人 :系统的规模是多少?
面试官 :系统每秒应该能生成 10000 个 id。
以上是你可以问面试官的一些问题。理解需求和澄清歧义是很重要的。对于这个面试问题,要求如下:
id 必须唯一。
id 仅为数值。
IDs 适合 64 位。
id 按日期排序。
每秒生成超过 10,000 个唯一 id 的能力。
第二步——提出高水平的设计并获得认同
在分布式系统中,可以使用多个选项来生成唯一的 id。我们考虑的选项有:
多主复制
【UUID】
票务服务器
推特雪花逼近
让我们来看看每一种方法,它们是如何工作的,以及每种方法的优缺点。
多主机复制
如图 7-2 所示,第一种方法是多主机复制。
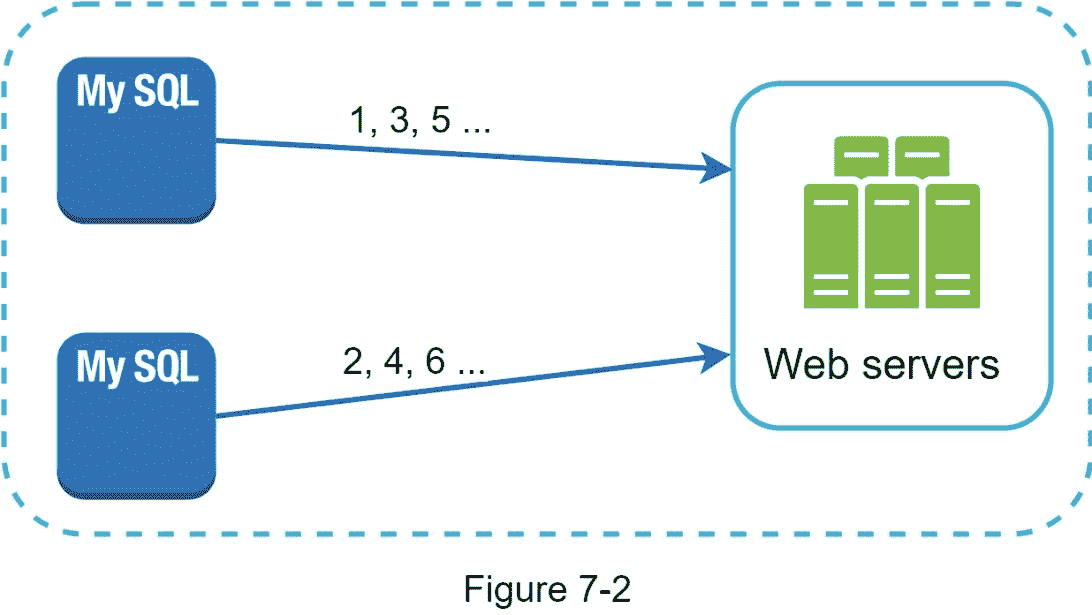
这种方式使用了数据库的auto _ increment特性。我们没有将下一个 ID 增加 1,而是增加了 k, ,其中 k 是正在使用的数据库服务器的数量。如图 7-2 所示,要生成的下一个 ID 等于同一服务器中的前一个 ID 加 2。这解决了一些可伸缩性问题,因为 IDs 可以随着数据库服务器的数量而伸缩。然而,这种策略有一些主要的缺点:
难以扩展多个数据中心
跨多台服务器的 IDs 不随时间上升。
添加或删除服务器时,它无法很好地扩展。
UUID
UUID 是获得唯一 ID 的另一种简单方法。UUID 是一个 128 位的数字,用于识别计算机系统中的信息。UUID 获得共谋的概率非常低。引用维基百科,“在大约 100 年内每秒生成 10 亿个 UUIDs 后,创建一个单一副本的概率会达到 50%”[1]。
下面举个 UUID 的例子:09 c93e 62-50 B4-468d-bf8a-c 07e 1040 bfb 2。可以独立生成,不需要服务器之间的协调。图 7-3 展示了 UUIDs 的设计。
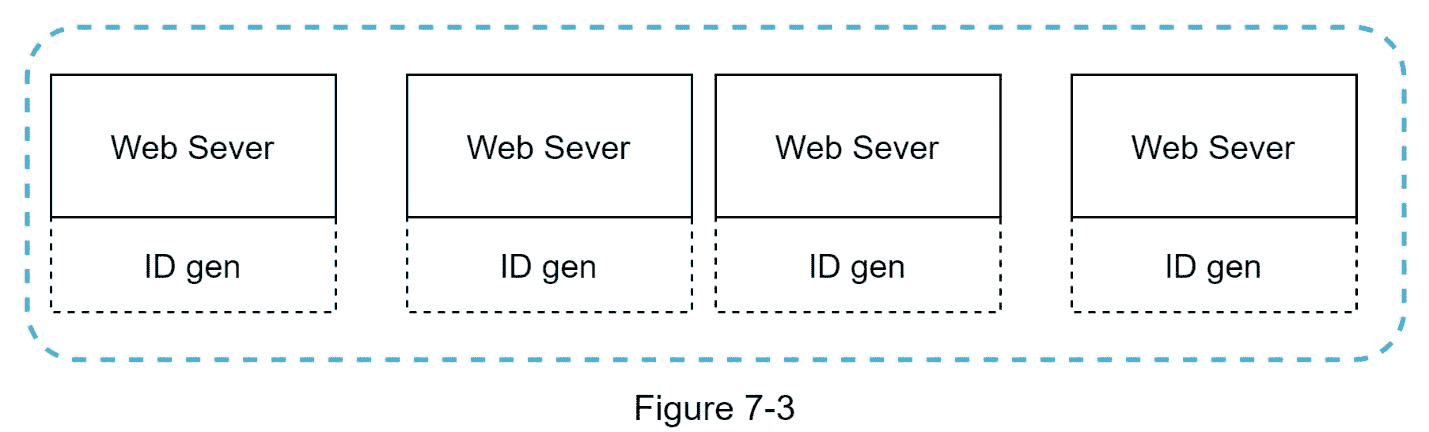
在这个设计中,每个 web 服务器都包含一个 ID 生成器,一个 web 服务器独立负责生成 ID。
优点:
生成 UUID 很简单。服务器之间不需要协调,所以不会有任何同步问题。
这个系统很容易扩展,因为每个 web 服务器负责生成它们所使用的 id。ID 生成器可以很容易地与 web 服务器一起伸缩。
缺点:
id 是 128 位长,但我们的要求是 64 位。
id 不随时间而涨。
id 可以是非数字的。
票务服务器
票证服务器是另一种生成唯一 id 的有趣方式。Flicker 开发了票证服务器来生成分布式主键[2]。值得一提的是这个系统是如何工作的。
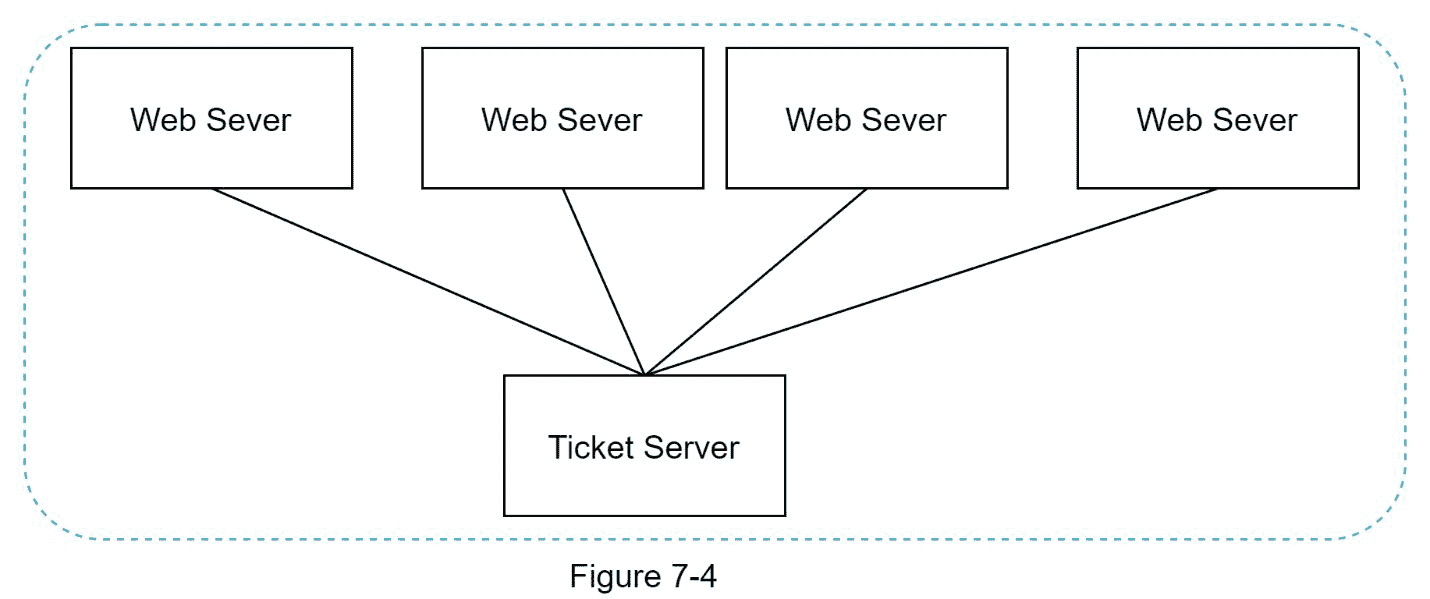
这个想法是在单个数据库服务器(票证服务器)中使用集中式的 自动增量 功能。要了解这方面的更多信息,请参考 flicker 的工程博客文章[2]。
优点:
数字标识。
易于实现,适用于中小型应用。
缺点:
单点故障。单一票证服务器意味着如果票证服务器宕机,所有依赖它的系统都将面临问题。为了避免单点故障,我们可以设置多个票证服务器。然而,这将引入新的挑战,例如数据同步。
推特雪花接近
上面提到的方法给了我们一些关于不同 ID 生成系统如何工作的想法。然而,它们都不符合我们的具体要求;因此,我们需要另一种方法。Twitter 独特的 ID 生成系统叫做“雪花”[3]很有启发性,可以满足我们的要求。
分而治之是我们的朋友。我们不是直接生成 ID,而是将 ID 分成不同的部分。图 7-5 显示了一个 64 位 ID 的布局。

每一部分解释如下。
标志位:1 位。它将永远是 0。这是为将来使用而保留的。它可以潜在地用于区分有符号和无符号数。
时间戳:41 位。自纪元或自定义纪元以来的毫秒数。我们使用 Twitter 雪花默认纪元 1288834974657,相当于 2010 年 11 月 4 日 01:42:54 UTC。
数据中心 ID: 5 位,这给了我们 2 ^ 5 = 32 数据中心。
机器 ID: 5 位,即每个数据中心有 2 台^ 5 = 32 台 机器。
序号:12 位 。对于在该机器/进程上生成的每个 ID,序列号增加 1。该数字每毫秒重置为 0。
步骤 3 -设计深度潜水
在概要设计中,我们讨论了在分布式系统中设计唯一 ID 生成器的各种方案。我们决定采用一种基于 Twitter 雪花 ID 生成器的方法。让我们深入研究一下这个设计。为了提醒我们,下面重新列出了设计图。

数据中心 id 和机器 id 在启动时选择,通常在系统启动运行后固定。数据中心 ID 和机器 ID 的任何更改都需要仔细检查,因为这些值的意外更改会导致 ID 冲突。ID 生成器运行时会生成时间戳和序列号。
时间戳
最重要的 41 位组成时间戳部分。随着时间戳随着时间的增长,id 可以按时间排序。图 7-7 显示了一个二进制表示如何转换成 UTC 的例子。您也可以使用类似的方法将 UTC 转换回二进制表示。
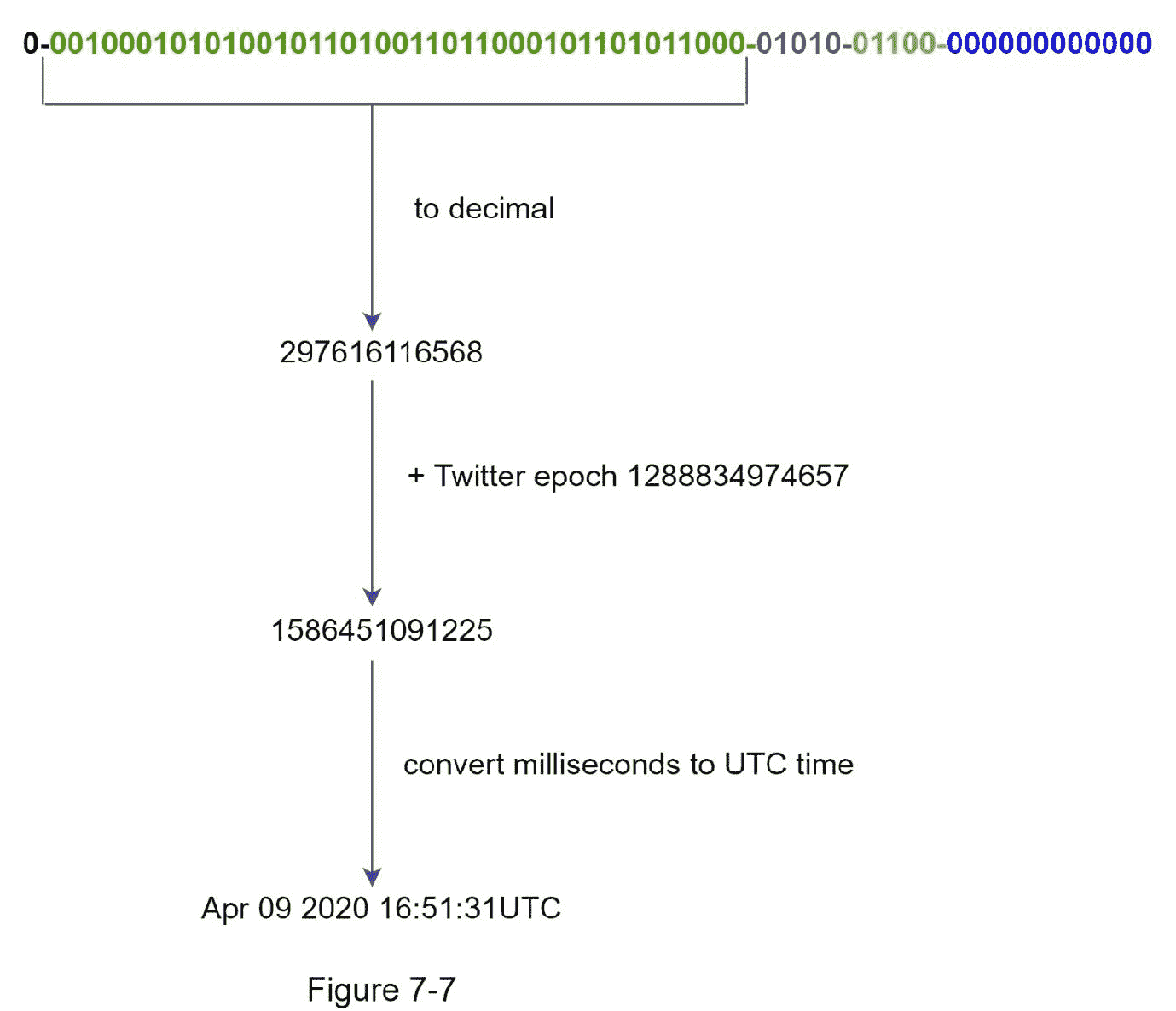
可以用 41 位表示的最大时间戳是
2 ^ 41 - 1 = 2199023255551 毫秒(ms),由此我们得到:~ 69 年=
2199023255551 毫秒/ 1000 秒/ 365 天/ 24 小时/ 3600 秒 。这意味着 ID 生成器将工作 69 年,拥有一个接近今天日期的自定义纪元时间会延迟溢出时间。69 年后,我们将需要一个新的纪元时间或采用其他技术来迁移 IDs。
序号
序列号是 12 位,这给我们 2 个^ 12 = 4096 个组合。除非在同一台服务器上一毫秒内生成了多个 ID,否则该字段为 0。理论上,一台机器每毫秒最多可以支持 4096 个新 id。
步骤 4 -总结
在本章中,我们讨论了设计唯一 ID 生成器的不同方法:多主机复制、UUID、票据服务器和 Twitter 雪花型唯一 ID 生成器。我们选择了雪花,因为它支持我们所有的用例,并且可以在分布式环境中扩展。
如果在采访结束时有额外的时间,这里有一些额外的谈话要点:
时钟同步。在我们的设计中,我们假设 ID 生成服务器具有相同的时钟。当服务器在多个内核上运行时,这种假设可能不成立。在多机场景中也存在同样的挑战。时钟同步的解决方案超出了本书的范围;然而,了解问题的存在是很重要的。网络时间协议是解决这个问题的最流行的方法。感兴趣的读者可以参考参考资料[4]。
分段长度调谐。例如,更少的序列号但更多的时间戳位对于低并发性和长期应用程序是有效的。
高可用性。因为 ID 生成器是一个任务关键型系统,所以它必须高度可用。
祝贺你走到这一步!现在给自己一个鼓励。干得好!
参考资料
【2】票服务器:廉价的分布式唯一主键:
【3】宣布雪花:https://blog . Twitter . com/engineering/en _ us/a/2010/Announcing-snow flake . html
