Kaggle 官方教程:机器学习入门5 欠拟合与过拟合
原文:Intro to Machine Learning > Underfitting and Overfitting
译者:Leytton
PS:水平有限,欢迎交流指正([email protected])
在这一步的最后,你将了解欠拟合和过拟合的概念,并将能够应用这些概念使你的模型更加准确。
1、尝试不同的模型
现在你已经有了一种可靠的方法来度量模型的准确性,你可以使用其他模型进行试验,看看哪个模型的预测效果最好。那么有哪些模型可选择呢?
你可以在scikit-learn的文档中看到,决策树模型有许多选项。最重要的选项决定了树的深度。回想一下这门微课程的第一节课,一棵树的深度是它在做出预测之前进行分裂次数的度量。这是一棵相对较浅的树:
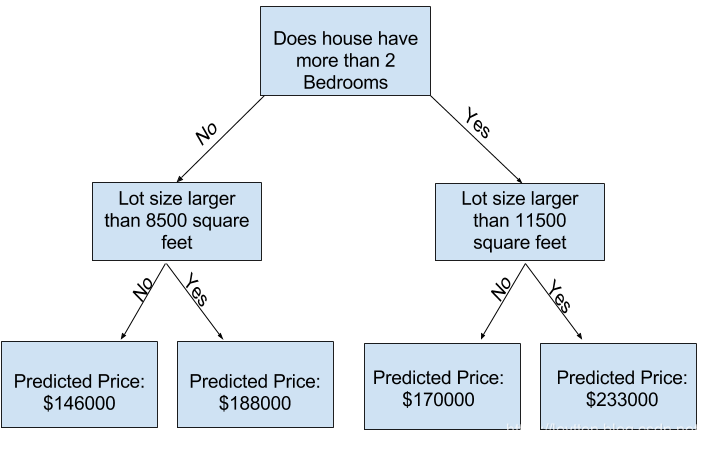
在实践中,一棵树的顶层(所有的房子)和一片叶子之间有10个分叉是很常见的。随着树越来越深,数据集被分割成具有更少房子的叶子。
如果一棵树只有一个分叉,它将数据分成两组。如果每组再分裂一次,我们会得到4组房子。再把它们分成8组。如果我们在每一层增加更多的分叉,使群组数量翻倍,到第10层时,我们将有2^10组房子。即1024片叶子。
当我们把房子分成许多片叶子时,每片叶子上的房子也就更少了。叶子上的房子越少,则预测值更接近房子的实际价值。但它们对新数据的预测可能非常不可靠(因为每个预测都只基于少数房子)。
这种现象叫做过拟合,模型与训练数据几乎完全匹配,但在验证其他新数据方面效果很差。另一方面,如果我们设计的树很浅,它不会把房子分成很明显的组。
在极端情况下,如果一棵树只有2或4个分支,则各个叶子仍然有各种各样的房子。这就导致预测房价相差甚远,即使是在训练数据中(由于这个原因,验证结果也会很糟糕)。当一个模型不能捕捉到数据中的重要特征和模式时,它在训练数据时就表现得很差,这称为欠拟合。
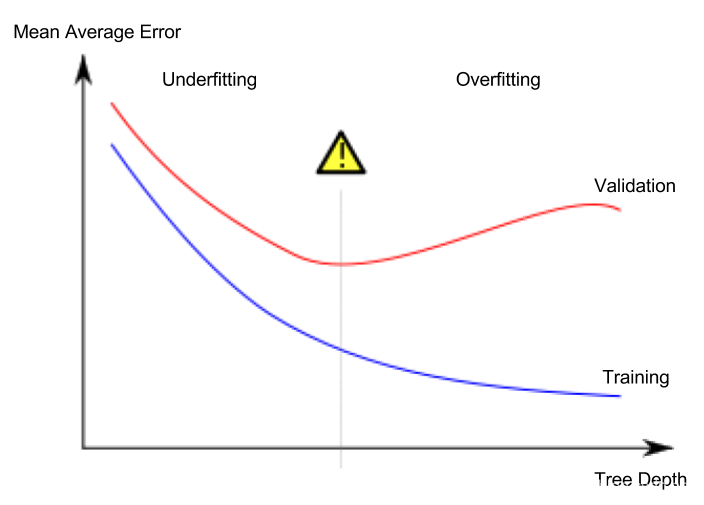
由于我们关心新数据的准确性,根据验证数据估算,我们希望在欠拟合和过拟合之间找到一个最佳点。在视觉上,我们想要(红色)验证曲线的最低点。
2、案例
有几种方法可以控制树的深度,树的一些路径可以比其他路径有更大的深度。但是max_leaf_nodes参数提供了一种非常合适的方法来控制过拟合和欠拟合。我们允许模型生成的叶子越多,在上图中就越接近过拟合区域。
我们可以使用一个实用函数来比较不同max_leaf_nodes值模型的MAE分数:
from sklearn.metrics import mean_absolute_error
from sklearn.tree import DecisionTreeRegressor
def get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y):
model = DecisionTreeRegressor(max_leaf_nodes=max_leaf_nodes, random_state=0)
model.fit(train_X, train_y)
preds_val = model.predict(val_X)
mae = mean_absolute_error(val_y, preds_val)
return(mae)
数据被加载进train_X, val_X, train_y 和 val_y 变量:
import pandas as pd
# 加载数据
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
# 过滤缺失数据
filtered_melbourne_data = melbourne_data.dropna(axis=0)
# 选择特征和目标值
y = filtered_melbourne_data.Price
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'BuildingArea',
'YearBuilt', 'Lattitude', 'Longtitude']
X = filtered_melbourne_data[melbourne_features]
from sklearn.model_selection import train_test_split
# 将数据分割为训练和验证数据,都有特征和预测目标值
train_X, val_X, train_y, val_y = train_test_split(X, y,random_state = 0)
我们可以使用for循环来比较使用不同max_leaf_nodes值构建模型的准确性。
# 比较不同max_leaf_nodes值的MAE
for max_leaf_nodes in [5, 50, 500, 5000]:
my_mae = get_mae(max_leaf_nodes, train_X, val_X, train_y, val_y)
print("Max leaf nodes: %d \t\t Mean Absolute Error: %d" %(max_leaf_nodes, my_mae))
输出数据:
Max leaf nodes: 5 Mean Absolute Error: 347380
Max leaf nodes: 50 Mean Absolute Error: 258171
Max leaf nodes: 500 Mean Absolute Error: 243495
Max leaf nodes: 5000 Mean Absolute Error: 254983
在列出的选项中,500个是最佳的叶子数。
3、结论
结论是,构建模型可能遇到这两种情况:
- 过拟合: 捕捉那些在未来不会重现的虚假模式,导致预测不那么准确。
- 欠拟合: 未能捕捉到相关的模式,导致预测不那么准确。
我们使用不参与模型训练的验证数据来度量候选模型的准确性。这让我们可以尝试多种候选模型后,保留最佳模型。
