Kaggle 官方教程:机器学习入门3 你的第一个机器学习模型
原文:Intro to Machine Learning > Your First Machine Learning Model
译者:Leytton
PS:水平有限,欢迎交流指正([email protected])
1、选择建模数据
原始数据集有太多的干扰变量,难以理解,甚至无法很好地打印出来。如何将这些数据处理为比较精简易懂呢?
我们先凭直觉选择几个变量。后面的课程将向你展示使用统计技术来自动优选变量。
选择变量/列前,我们先来看看数据集中有哪些列,使用DataFrame的columns属性来实现,代码如下:
import pandas as pd
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
melbourne_data = pd.read_csv(melbourne_file_path)
melbourne_data.columns
输出结果:
Index(['Suburb', 'Address', 'Rooms', 'Type', 'Price', 'Method', 'SellerG',
'Date', 'Distance', 'Postcode', 'Bedroom2', 'Bathroom', 'Car',
'Landsize', 'BuildingArea', 'YearBuilt', 'CouncilArea', 'Lattitude',
'Longtitude', 'Regionname', 'Propertycount'],
dtype='object')
- Melbourne 数据集有部分缺失(有些房子没有记录变量。)
- 我们将在后面的教程中学习如何处理缺失值。
- Iowa 数据没有缺失值。
- 现在我们将采用最简单的方法,从数据中删除掉数据缺失的房屋。
- 现在不要太担心这个,代码如下:
# dropna 删除有缺失的数据 (na可以看作是"not available")
melbourne_data = melbourne_data.dropna(axis=0)
有许多选择数据子集的方法,《Pandas微课程》将更深入地介绍这些内容,但目前我们将重点介绍两种方法。 There are many ways to select a subset of your data. The Pandas Micro-Course covers these in more depth, but we will focus on two approaches for now.
点符号,用来选择"预测目标";列数组, 用来选择“特性”。
2、选择预测目标
你可以用点符号来获取一个变量。这个单列存储在一个系列中,与只有单列数据的DataFrame非常类似。
我们将使用点符号来选择要预测的列,这称为预测目标。按照惯例,预测目标我们记为y,将房价保存到y变量的代码为:
y = melbourne_data.Price
3、选择特征值
输入到模型中的数据列(稍后用于进行预测)称为“特性”。在我们的例子中,这些数据列是用来确定房价。有时,你将使用除预测目标之外的所有数据列作为特性。但有时候,剔除无效的特征,预测效果会更好。
现在,我们将构建一个只包含几个特性的模型。稍后你将看到如何迭代和比较这些使用不同特性构建的模型。 我们通过在括号内提供列名列表来选择多个特性。列表中的每一项都应该是一个字符串(带引号)。
在数据集中提取多个特征列的代码如下(列名称应该是字符串类型):
melbourne_features = ['Rooms', 'Bathroom', 'Landsize', 'Lattitude', 'Longtitude']
按照惯例,这个数据称为X。
X = melbourne_data[melbourne_features]
我们快速地用describe方法与head方法,来查看数据概览:
X.describe()
输出结果:
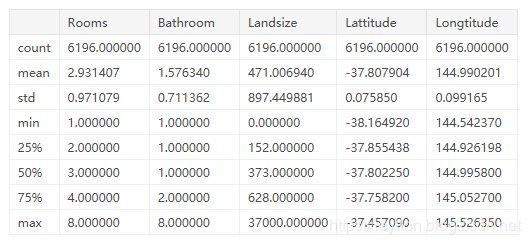
X.head()
输出结果:
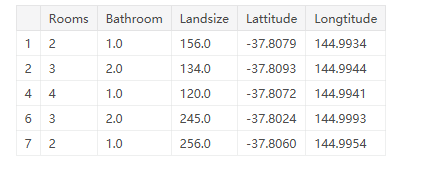
使用这些命令可视化地检查数据是数据科学家工作的一个重要部分,你会经常在其中发现值得进一步研究的惊喜。
4、构建模型
你将使用scikit-learn库创建模型。编写代码时,这个库被编写为sklearn,你将在示例代码中看到。Scikit-learn 很容易将处理存储在DataFrames中的数据进行建模,是最流行的库。
建立和使用模型的步骤如下:
定义: 它将是什么类型的模型?一个决策树吗?还是其他类型的模型?也指定了模型类型的一些参数。
拟合:从提供的数据中捕获模式,这是建模的核心。
预测:表面意思,这个就不说了
评估:确定模型的预测有多准确。
下面是一个用scikit-learn定义一个决策树模型,并用特性和目标变量进行拟合的例子:
from sklearn.tree import DecisionTreeRegressor
# 定义模型. 指定一个参数random_state确保每次运行结果一致
melbourne_model = DecisionTreeRegressor(random_state=1)
# 拟合模型
melbourne_model.fit(X, y)
输出结果:
DecisionTreeRegressor(criterion='mse', max_depth=None, max_features=None,
max_leaf_nodes=None, min_impurity_decrease=0.0,
min_impurity_split=None, min_samples_leaf=1,
min_samples_split=2, min_weight_fraction_leaf=0.0,
presort=False, random_state=1, splitter='best')
许多机器学习模型在模型训练中允许一定的随机性。为random_state指定一个数字可以确保每次运行得到相同的结果。这被认为是一种很好的做法。你使用任何数字,而模型的质量并不完全取决于你所选择的值。
我们现在有了一个拟合的模型,可以用来进行预测。
在实践中,你会想要预测即将上市的新房子,而不是我们已经有价格的房子。但我们将对训练数据的前几行进行预测,以了解predict函数是如何工作的。
print("Making predictions for the following 5 houses:")
print(X.head())
print("The predictions are")
print(melbourne_model.predict(X.head()))
输出结果:
Making predictions for the following 5 houses:
Rooms Bathroom Landsize Lattitude Longtitude
1 2 1.0 156.0 -37.8079 144.9934
2 3 2.0 134.0 -37.8093 144.9944
4 4 1.0 120.0 -37.8072 144.9941
6 3 2.0 245.0 -37.8024 144.9993
7 2 1.0 256.0 -37.8060 144.9954
The predictions are
[1035000. 1465000. 1600000. 1876000. 1636000.]
5、去吧,皮卡丘
在模型构建练习中自己尝试一下~
