Kaggle 官方教程:机器学习入门2 数据探索
原文:Intro to Machine Learning > Basic Data Exploration
译者:Leytton
PS:水平有限,欢迎交流指正([email protected])
1、使用Pandas熟悉数据
任何机器学习项目的第一步都是熟悉数据。你可以使用Pandas来实现。Pandas是数据科学家用来探索和操作数据的主要工具。大多数人在代码中将panda简写为pd,使用以下代码将其引用:
import pandas as pd
Pandas最重要的部分就是DataFrame了。DataFrame保存了类似表的数据类型,就像Excel中的工作表或SQL数据库中的表。
Pandas具有强大的函数来实现大部分你想要的数据操作。
举个例子,我们来看看澳大利亚墨尔本的房价数据。
数据文件路径在../input/melbourne-housing-snapshot/melb_data.csv。
我们使用以下命令来加载和查看数据:
# 文件路径
melbourne_file_path = '../input/melbourne-housing-snapshot/melb_data.csv'
# 读取并保存数据到DataFrame类型变量melbourne_data
melbourne_data = pd.read_csv(melbourne_file_path)
# 打印数据概览
melbourne_data.describe()
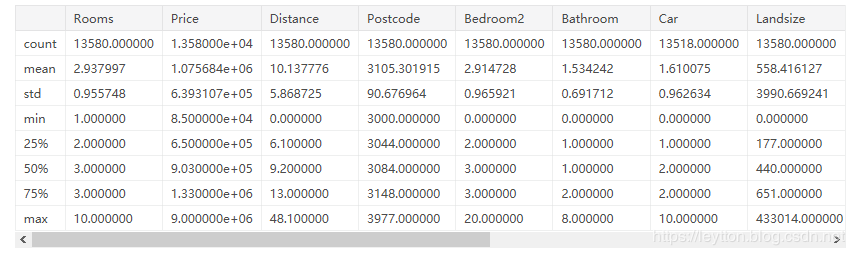
2、数据描述详解
如上图所示,结果打印了8个数据。第一个count显示有多少个未缺失的数据。缺失值的产生有很多原因。例如,本身只有一间卧室的房子,就不会存在第二间卧室的数据。我们重回数据缺失的主题。
第二个值是mean,也就是平均值。std是标准偏差,它体现了数据分布情况。
min和 max 比较好理解,分别是指最小值和最大值;
25%, 50%, 75%是指,我们将数据从小到大排列,返回25%,50%,75%数据量时的数字。
3、去吧,皮卡丘
从这里开启你的编程实战吧~
