Kaggle 官方教程:机器学习中级2 缺失值处理
原文:Intermediate Machine Learning > Missing Values
译者:Leytton
PS:水平有限,欢迎交流指正([email protected])
在本课程中,你将学习三种处理缺失值的方法。然后使用实际数据集比较这些方法的效果。
1、介绍
造成数据丢失的原因有很多。例如,
- 两间卧室的房子不包括第三间卧室的价值。
- 调查对象可能选择不分享其收入。
大多数机器学习库(包括scikit-learn)在试图使用缺失值的数据构建模型时都会出现错误。因此,你需要选择下面的策略之一。
2、三种方法
1) 一个简单的选择:删除缺少值的列
最简单的选择是删除缺少值的列。

除非删除列中的大多数值都丢失了,否则使用这种方法将丢失许多潜在价值的信息。举个极端的例子,假如有一个10,000行的数据集,其中一个重要的列缺少一条数据。这种方法将完全删除该列!
2) 一个更好的选择:填充
用一些数字填充缺失的值。例如,我们可以用平均值填充。
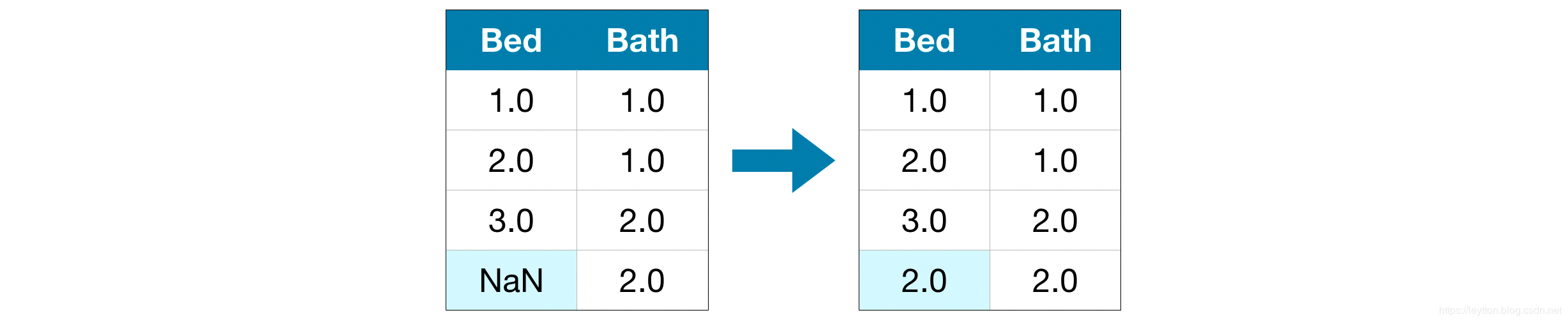
在大多数情况下,填充的值不一定正确,但它通常会比完全删除该列数据要好。
3) 填充扩展
填充是标准的方法,通常效果很好。然而,填充的值可能高于或低于实际值(数据集中没有收集这些值)。或者缺少值的行在某些方面可能是唯一的。在这种情况下,你的模型将考虑哪些值是最初丢失的,从而做出更好的预测。
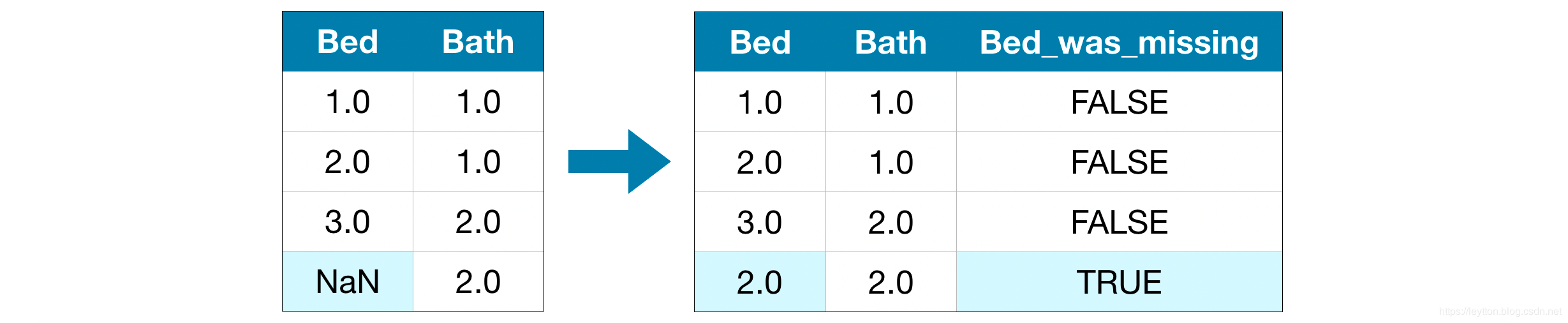
在这种方法中,我们像以前一样输入缺失的值。此外,新增一列用于记录哪条数据是缺失填充的。
在某些情况下,这将非常有效。但某些情况,这没有一点用。
3、案例
在本例中,我们将使用 Melbourne Housing 数据集。我们的模型将使用房间数量和土地面积等信息来预测房价。
我们不会关注数据加载步骤。相反,你可以想象你已经拥有了X_train、X_valid、y_train和y_valid中的训练和验证数据。
定义函数来评估每种方法的效果
我们定义了一个函数score_dataset()来比较处理缺失值的不同方法。该函数计算随机森林模型的平均绝对误差(MAE)。
方法1的得分(删除缺少值的列)
由于我们同时处理训练集和验证集,所以要注意在两个数据框中删除相同的列。
# 获取缺少值的列名称
cols_with_missing = [col for col in X_train.columns
if X_train[col].isnull().any()]
# 删除训练和验证数据中的列
reduced_X_train = X_train.drop(cols_with_missing, axis=1)
reduced_X_valid = X_valid.drop(cols_with_missing, axis=1)
print("MAE from Approach 1 (Drop columns with missing values):")
print(score_dataset(reduced_X_train, reduced_X_valid, y_train, y_valid))
输出结果:
MAE from Approach 1 (Drop columns with missing values):
183550.22137772635
方法2得分(填充)
接下来,我们使用SimpleImputer用每一列的平均值填充缺失的值。
虽然它很简单,但是填充平均值的方法通常很好用(不同数据集有所差异)。尽管统计学家已经尝试了更复杂的方法来确定填充值(例如回归填充),但一旦将结果插入复杂的机器学习模型,这些复杂的策略通常不会带来额外的好处。
from sklearn.impute import SimpleImputer
# 填充
my_imputer = SimpleImputer()
imputed_X_train = pd.DataFrame(my_imputer.fit_transform(X_train))
imputed_X_valid = pd.DataFrame(my_imputer.transform(X_valid))
# 填充移除了列名;补回来
imputed_X_train.columns = X_train.columns
imputed_X_valid.columns = X_valid.columns
print("MAE from Approach 2 (Imputation):")
print(score_dataset(imputed_X_train, imputed_X_valid, y_train, y_valid))
输出结果:
MAE from Approach 2 (Imputation):
178166.46269899711
我们看到方法2的MAE比方法1低,所以方法2在这个数据集中表现得更好。
方法3得分(填充扩展)
接下来,我们填充缺失的值,同时记录哪些值是填充的。
# Make copy to avoid changing original data (when imputing)
X_train_plus = X_train.copy()
X_valid_plus = X_valid.copy()
# Make new columns indicating what will be imputed
for col in cols_with_missing:
X_train_plus[col + '_was_missing'] = X_train_plus[col].isnull()
X_valid_plus[col + '_was_missing'] = X_valid_plus[col].isnull()
# Imputation
my_imputer = SimpleImputer()
imputed_X_train_plus = pd.DataFrame(my_imputer.fit_transform(X_train_plus))
imputed_X_valid_plus = pd.DataFrame(my_imputer.transform(X_valid_plus))
# Imputation removed column names; put them back
imputed_X_train_plus.columns = X_train_plus.columns
imputed_X_valid_plus.columns = X_valid_plus.columns
print("MAE from Approach 3 (An Extension to Imputation):")
print(score_dataset(imputed_X_train_plus, imputed_X_valid_plus, y_train, y_valid))
输出结果:
MAE from Approach 3 (An Extension to Imputation):
178927.503183954
正如我们所看到的,方法3的效果略差于方法2。
那么,为什么填充比删除列更好呢?
训练数据有10864行和12列,其中3列包含丢失的数据。对于每一列,缺少的条目不到一半。因此,删除列会删除很多有用的信息,因此填充方法效果会更好。
# Shape of training data (num_rows, num_columns)
print(X_train.shape)
# Number of missing values in each column of training data
missing_val_count_by_column = (X_train.isnull().sum())
print(missing_val_count_by_column[missing_val_count_by_column > 0])
输出结果:
(10864, 12)
Car 49
BuildingArea 5156
YearBuilt 4307
dtype: int64
4、结论
一般来说,比起简单地删除具有缺失值的列(在方法1中),填充缺失值(在方法2和方法3中)会得到更好的效果。
5、去吧,皮卡丘
在练习中比较处理缺失值的方法。
