Kaggle
![]()
你已经抓住了石头,现在是挥舞它的时候了!
- Kaggle 是一个流行的数据科学竞赛平台。
- GitHub 入门操作指南 和 Kaggle 入门操作指南,适合于学习过 MachineLearning(机器学习实战) 的小盆友
- Kaggle 已被 Google 收购,请参阅《谷歌收购 Kaggle 为什么会震动三界(AI、机器学习、数据科学界)》
Note:
- 号外号外: kaggle组队开始啦
- 比赛收集平台: https://github.com/iphysresearch/DataSciComp
- 关于 ApacheCN: 一边学习和整理,一边录制项目视频,希望能组建一个开源的公益团队对国内机器学习社区做一些贡献,同时也为装逼做准备!!
直播系列
kaggle入门系列
比赛直播系列
- 视频: 2019ICME 抖音视频理解 top2 solution 分享及 数据比赛入门讲解
- 文档: icme2019-top2.pptx
- 昊神GitHub地址: https://github.com/Smilexuhc
- 昊神整理比赛系列: https://github.com/Smilexuhc/Data-Competition-TopSolution
Kaggle 官方教程
机器学习入门
补充
竞赛
- 【推荐】特征工程全过程: https://www.cnblogs.com/jasonfreak/p/5448385.html
train loss 与 test loss 结果分析
- train loss 不断下降,test loss不断下降,说明网络仍在学习;
- train loss 不断下降,test loss趋于不变,说明网络过拟合;
- train loss 趋于不变,test loss不断下降,说明数据集100%有问题;
- train loss 趋于不变,test loss趋于不变,说明学习遇到瓶颈,需要减小学习率或批量数目;
- train loss 不断上升,test loss不断上升,说明网络结构设计不当,训练超参数设置不当,数据集经过清洗等问题。
机器学习比赛,奖金很高,业界承认分数。
现在我们已经准备好尝试 Kaggle 竞赛了,这些竞赛分成以下几个类别。
第1部分:课业比赛 InClass
课业比赛 InClass 是学校教授机器学习的老师留作业的地方,这里的竞赛有些会向public开放参赛,也有些仅仅是学校内部教学使用。
第2部分:入门比赛 Getting Started
入门比赛 Getting Started 给萌新们一个试水的机会,没有奖金,但有非常多的前辈经验可供学习。很久以前Kaggle这个栏目名称是101的时候,比赛题目还很多,但是现在只保留了9个最经典的入门竞赛:手写数字识别、沉船事故幸存估计、脸部识别、Julia语言入门。
第3部分:训练场 Playground
训练场 Playground里的题目以有趣为主,比如猫狗照片分类的问题。现在这个分类下的题目不算多,但是热度很高。
第4部分: 研究项目(少奖金) Research
研究型 Research 竞赛通常是机器学习前沿技术或者公益性质的题目。竞赛奖励可能是现金,也有一部分以会议邀请、发表论文的形式奖励。
第5部分:人才征募 Recruitment
人才征募 Recruitment 竞赛是赞助企业寻求数据科学家、算法设计人才的渠道。只允许个人参赛,不接受团队报名。
第6部分: 大型组织比赛(大奖金) Featured
推荐比赛 Featured 是瞄准商业问题带有奖金的公开竞赛。如果有幸赢得比赛,不但可以获得奖金,模型也可能会被竞赛赞助商应用到商业实践中呢。
第7部分: 限量邀请赛 Masters(新)
Masters(新) 限量参与比赛(受邀)
第8部分: 多评估标准赛 Analytics(新)
Analytics(新) 选择最优评估标准来排名的比赛
天池
其他部分
解决方案列表
如果解决方案太大,可以先放在这个列表中。以后再逐步整合到这个仓库。
机器学习算法
常用算法选择
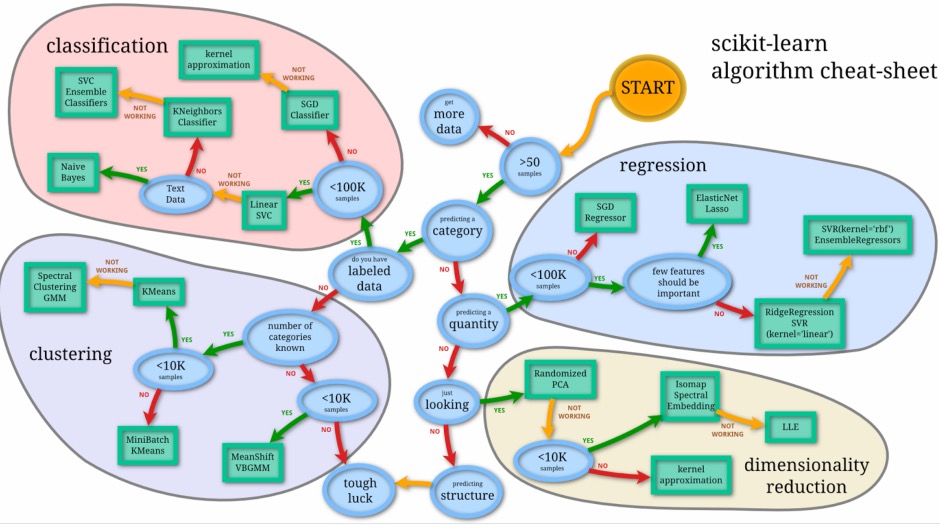
常用工具选择

解决问题的流程
- 链接场景和目标
- 链接评估准则
- 认识数据
- 数据预处理(清洗、调权)
- 特征工程
- 模型调参
- 模型状态分析
- 模型融合
数据预处理
- 数据清洗
- 去掉样本数据的异常数据。(比如连续型数据中的离群点)
- 去除缺失大量特征的数据
- 数据采样
- 下/上采样(假设正负样本比例1:100,把正样本的数量重复100次,这就叫上采样,也就是把比例小的样本放大。下采样同理,把比例大的数据抽取一部分,从而使比例变得接近于1;1)
- 保证样本均衡
- 工具 sql、pandas等
特征工程
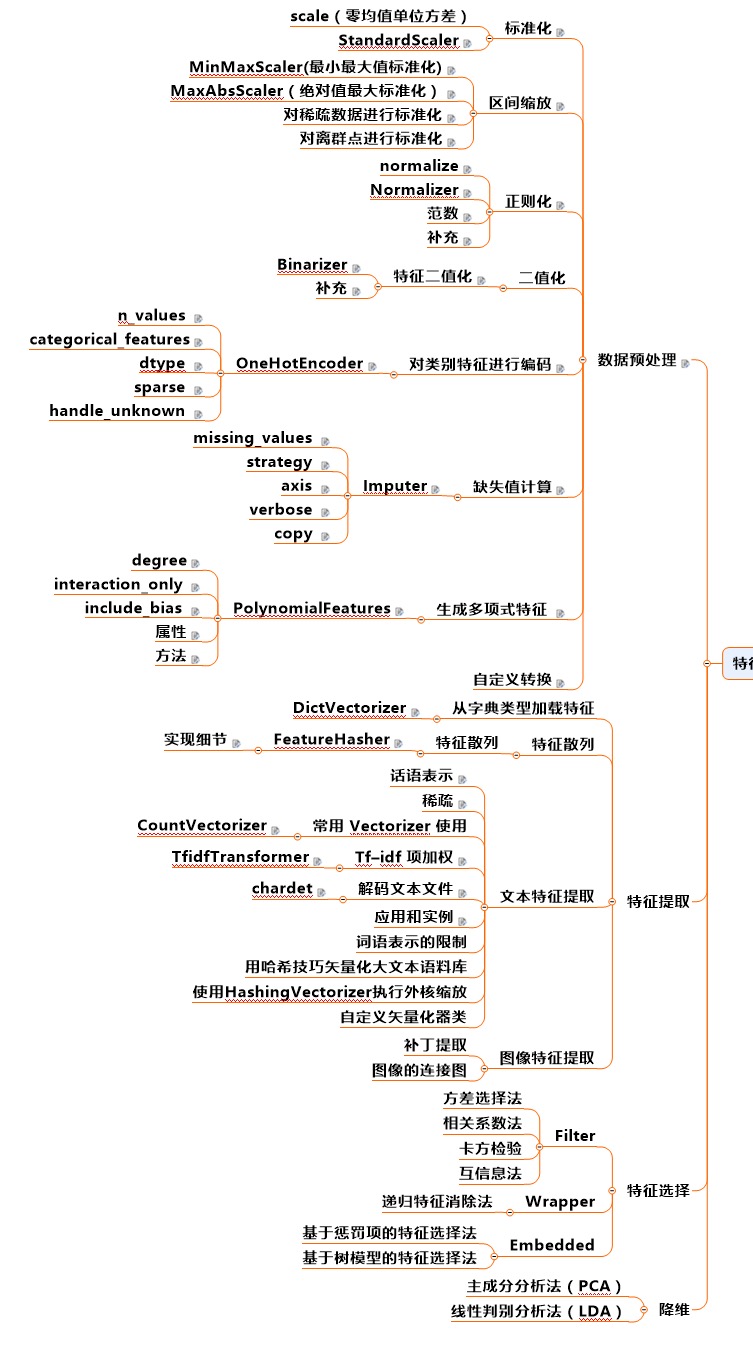
特征处理
- 数值型:连续型数据离散化或者归一化、数据变化(log、指数、box-cox)
- 类别型:做编码,eg:one-hot编码,如果类别数据有缺失,把缺失也作为一个类别即可。
- 时间类:间隔化(距离某个节日多少天)、与其他特征(eg:次数)融合,变成一周登陆几次、离散化(eg:外卖,把时间分为【饭店、非饭店】)
- 文本类:N-gram、Bag-of-words、TF-IDF
- 统计型:与业务强关联
- 组合特征
贡献指南
欢迎任何人参与和完善:一个人可以走的很快,但是一群人却可以走的更远
本项目接受大家提交 WriteUp(题解)。
WriteUp 需要带有预处理过程,从你能下载到的原始数据开始,并且带有验证过程和评价指标。
请放在/competitions/{分类}/{名称}目录下。
其中分类一共有六个,请见上面,名称是 URL 中/c/后面的部分。
